So you wanna build a Production-ready Serverless App?

I've been exploring serverless security for around a year now. Commonly, as a security pro, one typically looks at the offensive angle to any technology. While this can be very useful, it pales in comparison to the effort required in actually running and maintaining this technology, live, in production. And this is something that many of us security pros don't really understand.
All of this started with a essential need for our training programs. we45 delivers training programs all over the globe. We'll soon be at at BlackHat and we have a jam-packed year of trainings in the US, EU, Australia and Asia. One of the most important aspects of our training programs are our labs.
Labs are probably the most critical component of any technical training. Ours are no different. Not too long ago, our labs used to be like many others in the industry, where we would give our trainees VM images, that could be loaded on VMWare or Virtualbox. Audiences would typically have to download a 6-10GB VM image on their laptops and run it. This was painful. First of all, with more complex labs, we needed people to have really powerful laptop specs, which was a barrier. In addition, folks had to download HUUGE VM images to run things on their laptop. And last, but definitely not the least, VM tooling is extremely buggy and inconsistent on different environments. For example, Virtualbox on Windows has a host of compatibility issues.
In addition, our labs were constantly evolving. Especially for the topics we taught, like DevSecOps, Containers, Kubernetes, our labs had to keep pace with changing trends and technologies and VMs were not the solution.
We decided to move our labs to the cloud. This meant that each student gets a dedicated cloud environment on which they could run our labs. We debuted this at the AppSec California conference in Los Angeles earlier this year and it was an instant success. The labs were not only smooth and functional, but they were painless for the trainees. All they needed was a laptop and an SSH client.
However, we quickly started running into capacity issues here. We would have to provision the cloud servers for the trainees on the previous day, generate usernames and passwords for them, print them out on tiny pieces of paper, or labels and have them use this to access the class. Painful for us to execute.
In addition, SSH is not "always on". Audiences would start hitting "Broken Pipe" errors after some time. And while this experience was still better than most other trainings out there, we were not happy.
We wanted to create an experience, where a trainee can literally walk into one of our classes with an IPad, provision lab servers on demand through a system and run a dedicated lab with their dedicated lab environment. No messy labels with passwords on them, no SSH, no hiccups. And that's what we started building on June 20 2019
We decided to run an entirely serverless stack for this solution. The reasons were as follows:
- No managing any infrastructure elements - web servers, databases, etc. Managing them is a 24X7 job and we were not interested in doing that.
- No running into scale issues.
- Cost. Serverless gave us some amazing cost benefits that we wouldn't have seen with running our own infrastructure.
We decided to build out the following stack:
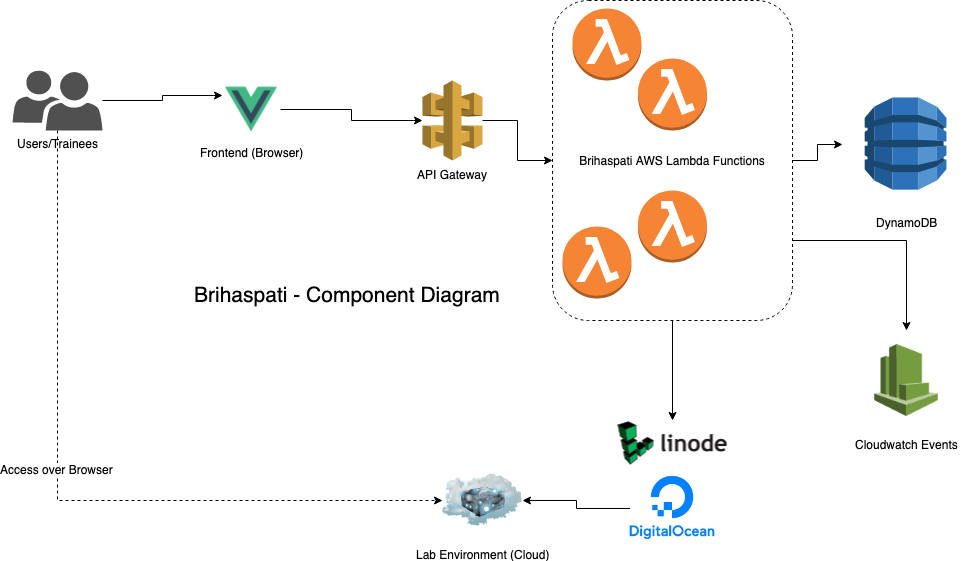
In this stack, all of the provisioner that we codenamed "Brihaspati" (Hindu God of Wisdom and the Teacher of the Gods).
The Stack
- Serverless Framework - Python
- Boto3
- AWS Lambda - Python (PynamoDB ORM)
- AWS DynamoDB
- CloudWatch Events
- Cloudwatch Logs
- Linode/Digitalocean
- VueJS - Front-end
- Netlify - Hosting the frontend
What Brihaspati does
- Brihaspati would be a 100% serverless app that would provision ephemeral lab environments based on our labs on Linode or Digitalocean and provide the student access to a dedicated entire lab, directly on the browser with no SSH involved.
- A student would login the Brihaspati portal for a particular class, say, DevSecOps Masterclass. The student would find all the labs related to that class. The student could press a play button to start the lab, that would provision an ephemeral lab environment on Linode/Digitalocean with the necessary lab and code related to the lab
- The student would run the lab and afterwards, turn off the lab or an automated expiration would kick in that would trigger a cloudwatch event that would delete the lab environment and scrub all the data from the lab environment.
Serverless as an Accelerator
One of the major observations for me personally, was that the entirely serverless aspect of this stack was a huge accelerant. We were able to finish the entire backend API and FaaS code with DynamoDB in 9 days flat. This, with a barebones front-end.
We leveraged the value of the Serverless Framework, with its YAML definition and built out individual functions in Python.
One of the major benefits of the Serverless Framework, vs other FaaS deployment tools like Chalice or Claudia, etc. is that there's a plethora of tooling available for this framework, including:
- Cold-start plugins
- Python packaging plugins
- Packaging and Compression plugins
In addition, managing IAM configuration for serverless.yml is much better than other tools I have used.
The Discipline Factor
One of the things I noticed when we built out this specific solution was the amount of discipline we applied to the project, especially because we embraced the constraints of the solution.
- Maybe it was me, but I found it much more "clear-cut" to implement TDD on this project than any other project before. Mentally, for a FaaS project, the developer thinks in terms of discrete functions, making it easier to validate and test, as a discrete unit.
- FaaS comes with an inherent set of constraints. Functions can't be long-running and you need to plan memory requirements for your function based on specific needs. While there are obvious downsides to this, its very important to consider and design your solution with this in mind. Leveraging queues or front-end polling are good ways to run long-running events. If the long-running event is complex, then it maybe even worthwhile to run them as Fargate jobs or Step-Functions
Serverless - Challenges
Cold Starts
Hands-down, the biggest challenge one faces when running a serverless stack as an API is Cold-Starts. Cold-Start is a process of loading a function to be executed when invoked. For a function to be running, it needs to be invoked, where:
- the cloud provider allocates a worker server
- the files and code is mounted to the server with settings
- the code and dependencies are loaded with a specific run-time
- the code runs!
This, as you can imagine creates significant latency, especially when the function hasn't been invoked for some time and needs to be "thawed".
We had some serious challenges with this to begin with.
- We are running serverless functions as API supported by a Reactive VueJS front-end. We saw a lot of cold-start issues causing front-end events and actions to fail. We had to "warm up" the functions with the
serverless-warmup-pluginto ensure that user-facing functions that were supported by the frontend were constantly "kept warm" by repeated invocations. This ensures that you get to Step 4 (above) with minimal latency - We also increased memory to specific functions to reduce the effect of cold-starts on the overall solution
DIY Input Validation and Error Handling
While this is not specifically a challenge, its important to consider this as a major "to be done" item while running serverless functions in production. Input Validation and Error Handling needs to be implemented per function, adding a great deal of time and effort to writing the function itself. In addition, since we didn't use AWS Cognito or some other Authentication service, we had to include authorization validation checks in each function
CloudFormation 200 limit
This stack was a pretty large stack of serverless functions and associated resources. What we didnt know was that Cloudformation has a limit per stack that you create. Cloudformation allows you to create upto 200 resources per stack. And while we didnt have 200 resources (API endpoints), we realized that each serverless function definition generates upto 6 resources in Cloudformation when deployed.
For example, for every single Lambda Function, you create the following resources:
AWS::Lambda::Permission, for the API Gateway to invoke the functionAWS::ApiGateway::Resource, configuring the resource path for the API endpointAWS:ApiGateway::Method, configuring the HTTP method for the API endpoint
Aside from this, you end up creating resources like AWS::ApiGateway::RestApi and AWS::IAM::Role for HTTP events
As a result, we saw that we had exceeded the limit for the Cloudformation stack size.
One solution was to break up the service into microservices. But that would have meant multiple endpoint URLs for the API Gateway call.
Finally, we settled on the serverless-split-stacks plugin. This plugin packages lambda functions into nested stacks to get past the 200 limit imposed by CloudFormation. It was very easy to implement and we were able to pull it off without a hitch, at the end
Conclusions
This was a very interesting project for us, that I am happy to see we've succeeded at. However, there were some key learnings in the process, and they are:
- A lot of folks assume that you can just use a deployment manager to convert your existing app or API into serverless. And while that's possible, its not recommended. Serverless comes with some specific opportunities and constraints and designing apps to be "serverless first" is an important distinction that you need to understand
- When running a serverless API supported by a front-end, you'll need to engineer your front-end to support and handle the possible adverse effects of cold-starts. This is a major issue that we understood and overcame, the hard way.
- Do not discount DIY input validation. Its very very important and you need to do it diligently and without exception
- Highly encourage using TDD while building out serverless. Makes life much easier when you need to be debugging things.