The Hard Way: Security Learnings from Real-world GraphQL

This article comes (relatively) close on the heels of my talk at AppSec California. The talk was:
"An Attacker's Perspective of Serverless and GraphQL Applications"
The slides for that talk are available here
As I was preparing for the talk. I had a project, ThreatPlaybook, that we needed to revamp. Being the lead developer on that project, I got to decide the tech-stack we were going to use on that project.
Just FYI, ThreatPlaybook is a "Threat-Modeling-as-Code" Framework that allows you to capture Codified Threat Models and combine that with targeted AppSec Automation. Sidenote: You should check it out, if you're interested in DevSecOps, Threat Modeling or anything in middle
Previously, ThreatPlaybook was a CLI that directly connected to a Database. However, with several people (not only we45) using it, I realized that I had to make this a more distributed application. ThreatPlaybook was much more than just a Threat Modeling Application. It was really a "unified DevSecOps" framework which included Threat Modeling.
So we came up with a more distributed architecture for our V3 Release

For the API, I decided to go with GraphQL, for the following reasons:
- I wanted to learn GraphQL in-depth. There was no better way to do it than a ground-up project like this
- Too often, as security folks, we deliver advice without truly understanding the constraints and challenges that goes into implementing said advice. GraphQL was something that I was working on (security) and I wanted to experience it for myself as a developer. Warts and all.
- I truly believed that GraphQL made sense for this application. This was a query-heavy application and would have had a ton of URI endpoints that would have been frustrating to write. I hate managing routes in APIs, so GraphQL was great. In addition, people ignore the "write benefit" that GraphQL gives with its mutations. Its great for pushing data into a system, previously possible with webhooks and all that (again, painful to manage as a developer).
Since ThreatPlaybook was initially a Python application, I decided to go with the following components:
ThreatPlaybook API
- Python 3.6
- Responder HTTP Framework
- Graphene-Python (GraphQL)
- Graphene-MongoEngine
- MongoEngine (ODM for Mongo)
I'm not covering the other components here as its not relevant to this article
As I started implementing GraphQL to be the API for this application, I came across the following bottlenecks/challenges that I believe should be security considerations for anyone implementing GraphQL. I also understand that the language and platform that you write your GraphQL application in, influences security. Example: NodeJS vs Python, etc. Since you have better security libraries for NodeJS GraphQL implementations vis a vis Python
Language/Platform Matters
One of the first things I noticed as I started writing GraphQL for my Python application, is the limited tooling and libraries available for GraphQL for Python. Sure, you have Graphene (library for GraphQL), but from a security perspective, there's very little that's out there for GraphQL in general itself, and lesser for Python. I had to write a lot of validation and error handling code myself, which is not ideal when you want to scale with it across a large/medium-sized team.
Input Validation is Hard!
I come from a "Framework First" approach to web development. This means that I typically use frameworks that automatically do Input Validation, Output Encoding, CSRF Handling, etc by default. Validation (especially for common use-cases) is something that I'd rather have the framework handle. Validation for simple data types like email, etc are something that I typically expected from frameworks. With this experience with GraphQL, all that was thrown out the window.
I had to handle Input Validation from scratch for all my user-generated events that led to GraphQL queries. GraphQL Schema allows you to use generic datatypes like String, Integer, Boolean. In addition, you can also use List, JSON, etc for nested or more complex objects. However, Input Validation of what actually goes into those fields are really your problem. I ended up implementing Regex for most of my validations.
Losing it over Loose Queries a.k.a No Client
One of the great flexibilities that GraphQL offers is your ability to perform dynamic (loose) queries on your data and fetch/mutate based on specific fields. This looks something like this:
As you can see from the above, I am querying a bunch of parent-child objects. I am querying User Stories => Abuser Stories => Threat Models => Security Test Cases and their various attributes in the same query. Obviously, this functionality is awesome when you are working with a GraphQL client like I am.
However, the situation is very different when you want to allow user-controlled query elements (through some middleware, in my case CLI) to dynamically query stuff in GraphQL, with a reasonable amount of security. In this case, you'll need to do:
- Input Validation => for complex datasets including
listtypes and object types - Dynamic Querying itself
During my quest to find a good client library for GraphQL, I was shocked to find that no client library could help me achieve this. The standard way to write a client query is something like this:
abuser_mutation_query =
"""
mutation {
createOrUpdateAbuserStory(
shortName: "%s",
description: "%s",
userStory: "%s"
project: "%s"
) {
abuserStory {
shortName
}
}
}
""" % (single['name'], single['description'], user_story_short_name, db.get('project'))As you can see from the above, I am using (gasp) format strings to concatenate string values with my mutation structure and make a query to my GraphQL API. Anyone who's had any experience with SQL Injection, Template Injection, or any other Injection attack would start sweating at the sight of the above. However, I am constrained to tell you...
THERE's NO OTHER WAY!
At least for Python. Apollo Client in JavaScript is a little better, but, its still pretty much concat.
So, security pros, if you run into this with your developers, please understand that you can't give them the "Parameterize your queries" spiel. It doesn't work.
Most GraphQL Client apps, do not recognize the possibility of injection attacks. In fact, for more complex queries, I started using jinja2 templates and populating them with my variables
def template_test_case_mutation():
mutation = """
mutation {
createOrUpdateTestCase(
singleCase: {
{% for key, value in mutation_vars.items() %}
{% if value['type'] == "string" %}
{{ key }}: "{{ value['name'] }}"
{% elif value['type'] == "list" %}
{{ key }}: {{ value['name']|tojson }}
{% else %}
{{ key }}: {{ value['name'] }}
{% endif %}
{% endfor %}
}
) {
case {
name
}
}
}
"""
return Template(mutation)As you can see from the above, this is a much better solution if you have a lot of optional variables, but still, far from perfect
This was probably the greatest struggle for me, as a developer and a security professional.
Introspection without Permission
One of the common security issues with GraphQL is the ability to "introspect". Introspection is the functionality where a user can get the schema and queries supported by the GraphQL Application. This, from an attacker's perspective is great, because the attacker can get detailed info the model, its attributes and attempt various subversions with this knowledge of the system.
In my GraphQL App, I implemented access control and a Stateless authorization system with JWT. I was hoping that this would disallow a user from introspection as well.
I was wrong
Introspection is a feature of GraphQL and while some servers allow them being turned on/off (Apollo Server, etc), Graphene-Python DOES NOT (link).
So, with my application, this means that while I can't perform any queries/mutations as an unauthenticated user. I can still see all the possible queries and mutations possible against my application with the GraphQL introspection view
When coupled with other vulnerabilities like Insecure Direct Object Reference or other Authentication/Authorization bypass flaws, this can be really bad.
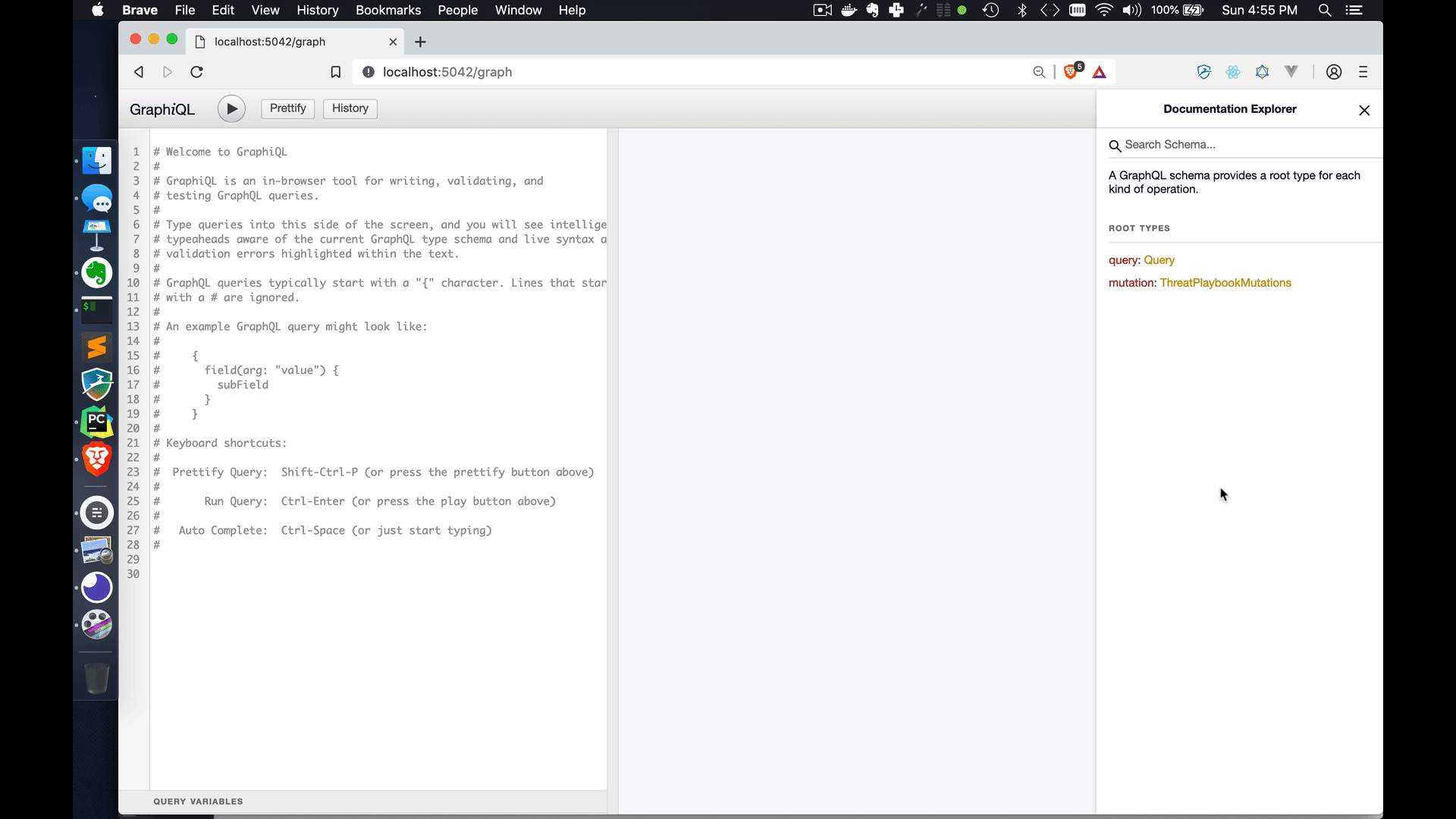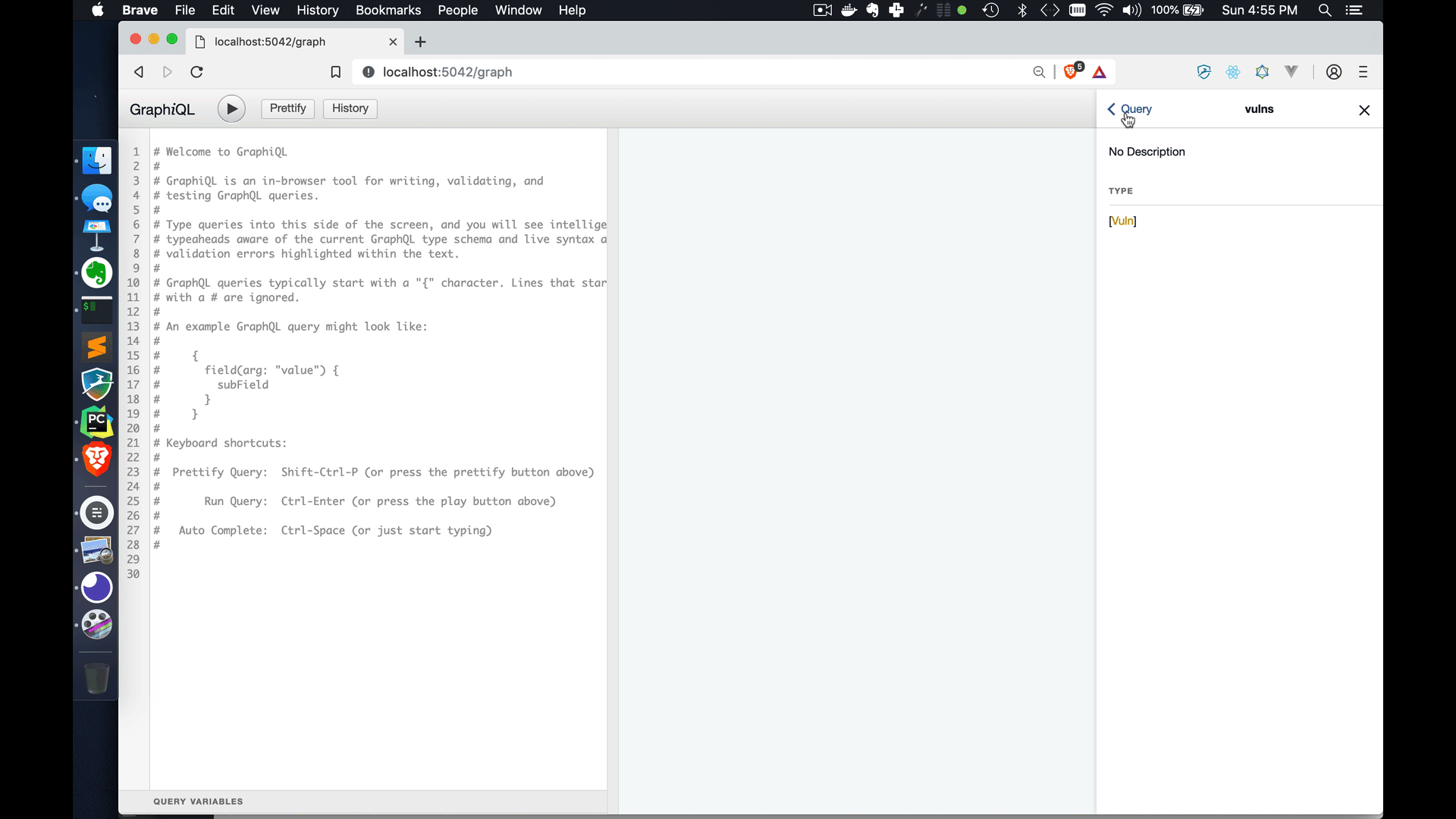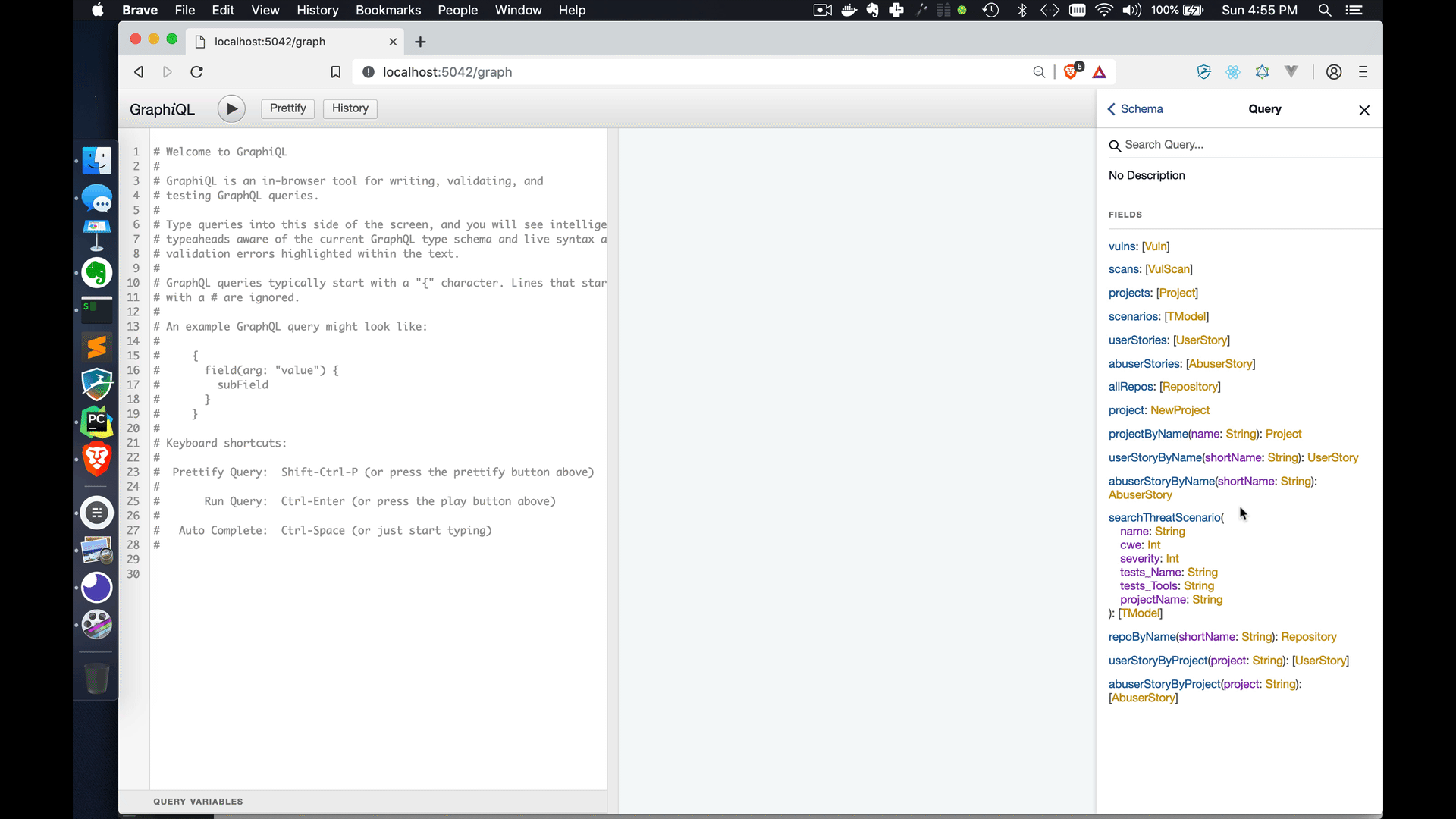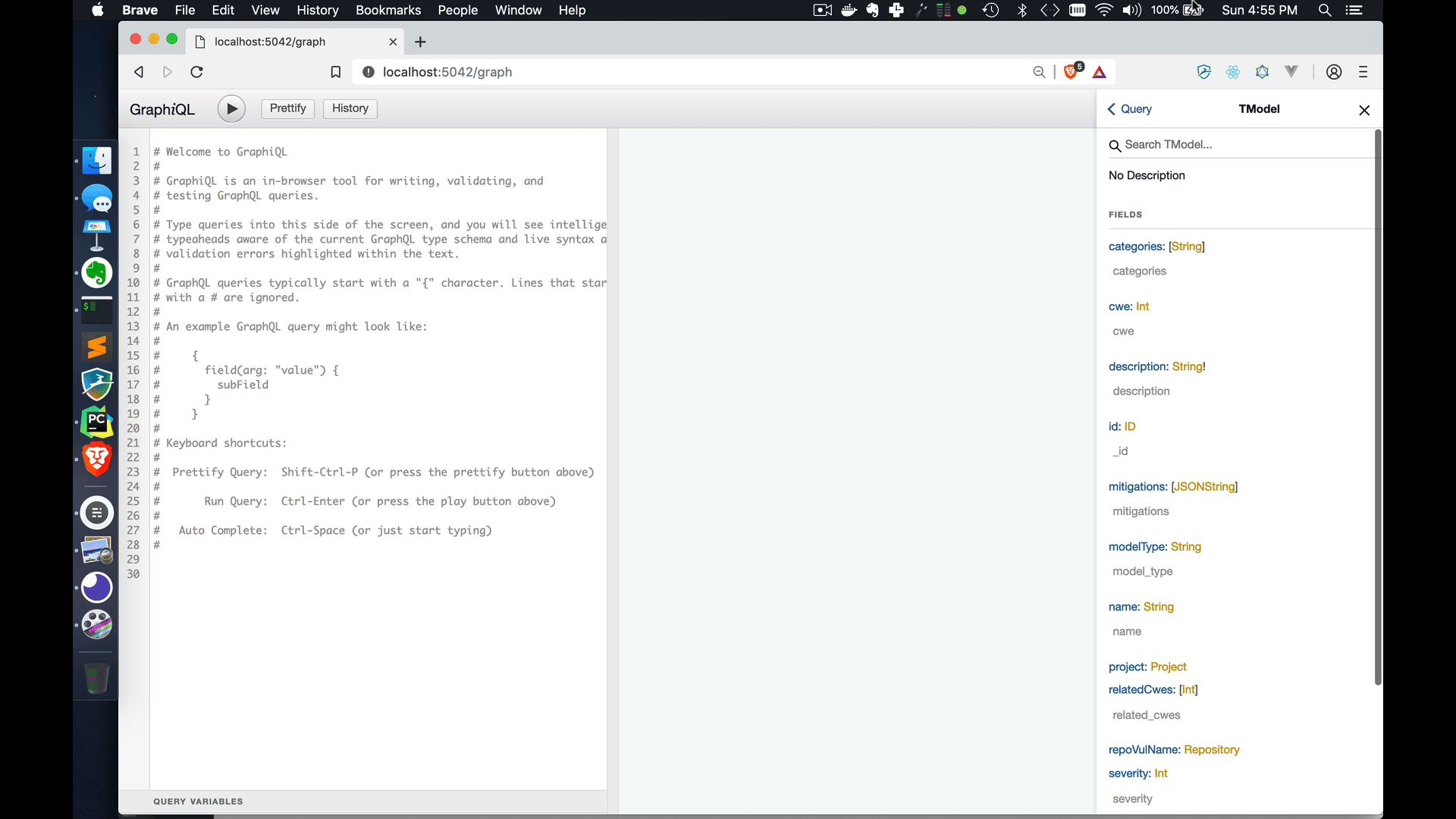
As you can see in the above image, I am able to get a detailed perspective of all the different objects and attributes in my app with GraphQL Introspection, even though I am not an authenticated user.
Validate Response
Typically HTTP REST API is reasonably easy to understand. You're mostly good if you get a HTTP 200 response, indicating that you have successfully performed X. If you end up with other responses, like 403, 500 etc you know you've/application has messed up somewhere and you can parse the response for more analysis.
With GraphQL, you need to validate the server responses deeply simply because everything comes back with an HTTP 200. So if you want to know if your data was inserted successfully by that GraphQL Mutation (Endpoint that allows you to insert/update data in your backend through graphql), then you need to validate responses in JSON to ensure that there are no errors or unexpected conditions.
This is where PyJQ was a lifesaver. Its the python port of the popular CLI tool jq. I used PyJQ to validate the response to check if the function worked correctly
#Mutation to add User Story into ThreatPlaybook
mutation {
createOrUpdateUserStory(
description: "As an administrator, I would like to validate logs of a user so I can identify anomalies in user behavior"
shortName: "admin_access"
project: "test_pro"
) {
userStory {
shortName
description
}
}
}
# Response from the Mutation
{
"data": {
"createOrUpdateUserStory": {
"userStory": {
"shortName": "admin_access",
"description": "As an administrator, I would like to validate logs of a user so I can identify anomalies in user behavior"
}
}
}
}
#Validation with pyjq
def validate_user_story(content):
return pyjq.first('.data.createOrUpdateUserStory.userStory.shortName',content)
Conclusions
GraphQL is powerful tech. And I truly believe that its a great replacement from REST APIs as we know them today. However, there are these and other security and scalability considerations that you must keep in mind when using or planning to use GraphQL.
In most successful Application Security programs, I have seen the use of secure defaults, or secure frameworks, etc, where the developers need to think very little to before writing what actually becomes reasonably secure code.
With GraphQL, achieving that state, is a ways off.
I believe that writing GraphQL requires a deeper thought into your Threat Model and a lot more discipline in the SDLC
To Security Pros:
Please don't rehash generic Application Security advice when dealing with these new paradigms of technology, like Serverless and GraphQL. There are a lot of erstwhile solutions that don't make any sense to these abstractions. Please take the time to understand the developer's concerns and constraints before railing on them.