Think "Feedback" over "Pipelines" for DevSecOps Success


For a while now, the term DevSecOps has become synonymous with Pipelines. That is natural. DevOps, for the longest time has been associated with pipelines. I am sure, that if you've read anything around DevOps or DevSecOps, you'd have heard of the term "CI/CD". Well, let's look at what these words mean before we get into the idea of "Feedback"
TL;DR Version of this article
I have covered some of what I discuss in this article in my talk recently at OWASP AppSec California. Here's my diatribe on YouTube
Continuous Integration (CI)
Continuous Integration is typically seen as the practice of developers contributing to a shared repository, several times a day. Each integration is then verified by a battery of automated tests and build steps. The way I see it, there are some key reasons why CI is important:
- Identifying issues with the (to-be-delivered) application earlier in the SDL, so issues can be identified (and fixed) before the application goes to production
- Ensuring that the code, at any given point in time, is imminently deployable. Not necessarily deployed, mind you. The idea behind a good CI process is to ensure that the code is deployable to any environment, and runs as expected, when deployed.
- Visibility and Accountability. Successful CI workflows are silent. But if CI processes break because of a failed test or a failed build, etc, then there's instant visibility and accountability. Visibility in that, the team is immediately made aware that a build has failed for X reason. Accountability in that, the build or CI process has failed because of X reason, that can be fixed by Y developer(s).
Continuous Deployment (CD)
Continuous Deployment is the natural extension to the question "How and Where do I deploy this, after the build is done?" Example - We at we45 work with Containers, Serverless Applications and more traditional applications that deploy as Server images on our cloud provider. For example, once we finish the CI Process, the code is:
- Built into a container image from a Dockerfile
- Push container image to the Registry. We use gitlab
- Deploy those images to a Kubernetes Cluster.
- Run End-t0-End tests on the Kubernetes Cluster to ensure that everything is working
As you can glean from this entire process, this is done in a completely automated way. Whenever code is pushed to the master branch of our source repository, it is considered deployable at that point and the CD process takes over, once the CI process is done building it and running unit tests.
Pipelines and DevSecOps - The Odd Couple
Most of what I have described above with CI and CD is typically done as a Pipeline. There's a set of tasks that run sequentially (and parallel in some cases) and deliver the flow for the CI and CD related tasks. However, Security has traditionally delivered mixed results when included in this pipeline. And that's for the following reasons:
Fidelity
Most of the tests in a CI and CD pipeline are either unit or functional tests. These are specific, high-fidelity tests that are specific to an application or a set of services. This is a significant departure from most security tools that are more fuzzing and rules-driven.
For example - A Static Code Analysis tool, no matter how fast, will read code, line-by-line, match it against its rulebase, and produce security findings. Worse, if that Static Code Analysis tool uses a system of source and sinks, where it attempts to identify all possible uses of a vulnerable function call or variable declaration, then it takes even longer for the analysis. And that doesn't include the boatload of false positives that are produced when this happens. That's why you see Enterprise SAST tools take an hour or longer to scan codebases for security flaws. While I cant name specific tools. I can say that one of the tools that takes an inordinate amount of time, while still producing a boatload of false positives, is a tool that rhymes with the word "Mortify" 😉
Therefore, Tools for SAST (Static Analysis) and DAST (Dynamic Analysis) find it hard to find a useful, permanent place in the CI/CD process because they are always seen in contrast to the super-quick runtimes of the existing integration or unit tests that always seem to run in seconds.
Poor Understanding and Monoculture
While this is improving by leaps and bounds, I still find that Security folks don't get DevOps or Continuous Delivery. And the DevOps or CD people don't get security, especially its limitations.
Security folks have a very unbending, utopian mindset of what a CI/CD process "should look like" without understanding the objectives or the inherent motivations for why its there in the first place. I blame "thought leaders" in DevSecOps for this. Many have little to no experience actually implementing or doing DevSecOps work, and they come up with catchy conclusions that people take way too seriously.
This is similar with DevOps folks' understanding of Security and security tools. I have seen customer meetings, where they have ridiculous expectations thrown around on security tools and what they can do.
Lack of understanding produces a monoculture. A culture of "this is right and everything else is wrong". Which IMO is the opposite of what DevOps (and DevSecOps) should be. There's no one-size-fits-all. There never was. There never will be.
Let's think "Feedback"
I love working with asynchronous workflows. I think there's something inherently "human" with asynchronous workflows. We are creatures that respond to Feedback. And I think leveraging that idea is a good way to go for a lot of us doing DevOps and/or DevSecOps.
Also, in case you were wondering Feedback-driven systems are all around us and shape our daily communication quite comprehensively. For example:
- Slack
- Github Pull Requests
- Jira tickets
are all examples of Feedback-driven systems that we use quite extensively on a daily basis.
Feedback-driven systems are inherently event-driven, rather than driven as a pipeline (or a set of sequential tasks). My point here is to view Security tasks in the erstwhile or mythical pipeline as a set of event-driven workflows that constantly deliver feedback to the people that it matters to. For example:
- Developer commits code => Opens Pull Request => Automated workflow runs SAST scans against code in PR and writes feedback to PR
- Application is deployed to staging => Triggers webhook to Dynamic Scanner/Vulnerability Scanner that scans target environment for vulnerabilities => writes results to Slack/Jira/Vulnerabiliy Management Tool
- Change to a Container image pushed to registry => triggers a security scan of the container image and dependencies => results pushed to Slack/Jira/Vulnerability Management Tool
- Change to a Stack deployed in Amazon => triggers a scan of the IAM policies used for the stack => Any security flaws (like * rules) are written as feedback to Slack/Jira/Vulnerability Management tool
Notice that you're still doing nearly (or more) security tasks as part of these event-driven workflows. However, in contrast to a "Pipeline" you are doing it in a:
- Event-driven way: No pressure on a pipeline to run these tools in under 30 seconds or some other threshold.
- Decentralized way: No single point of failure. Workflows are triggered at separate stages of the SDL
In addition, Event-driven approaches are more secure, because you don't need to deploy persistent infrastructure like Jenkins to run these flows. You can easily trigger them from containers or other ephemeral infrastructure like a Lambda function and get moving. Jenkins and CI tools are usually compromised quite easily owing to the massive security flaws in their plugin ecosystem or in the core application itself.
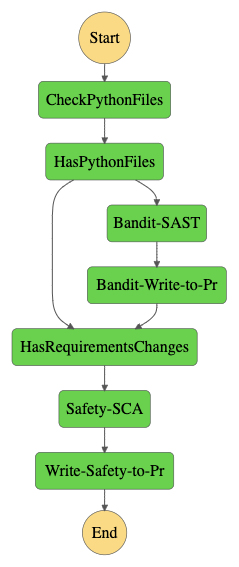
The other major benefit of "Feedback-Based" Decentralized Workflows is the Security of the infrastructure running these tasks in the first place.
As I am writing this, I am staring at a massive list of CVEs released for Jenkins and its allied plugins.
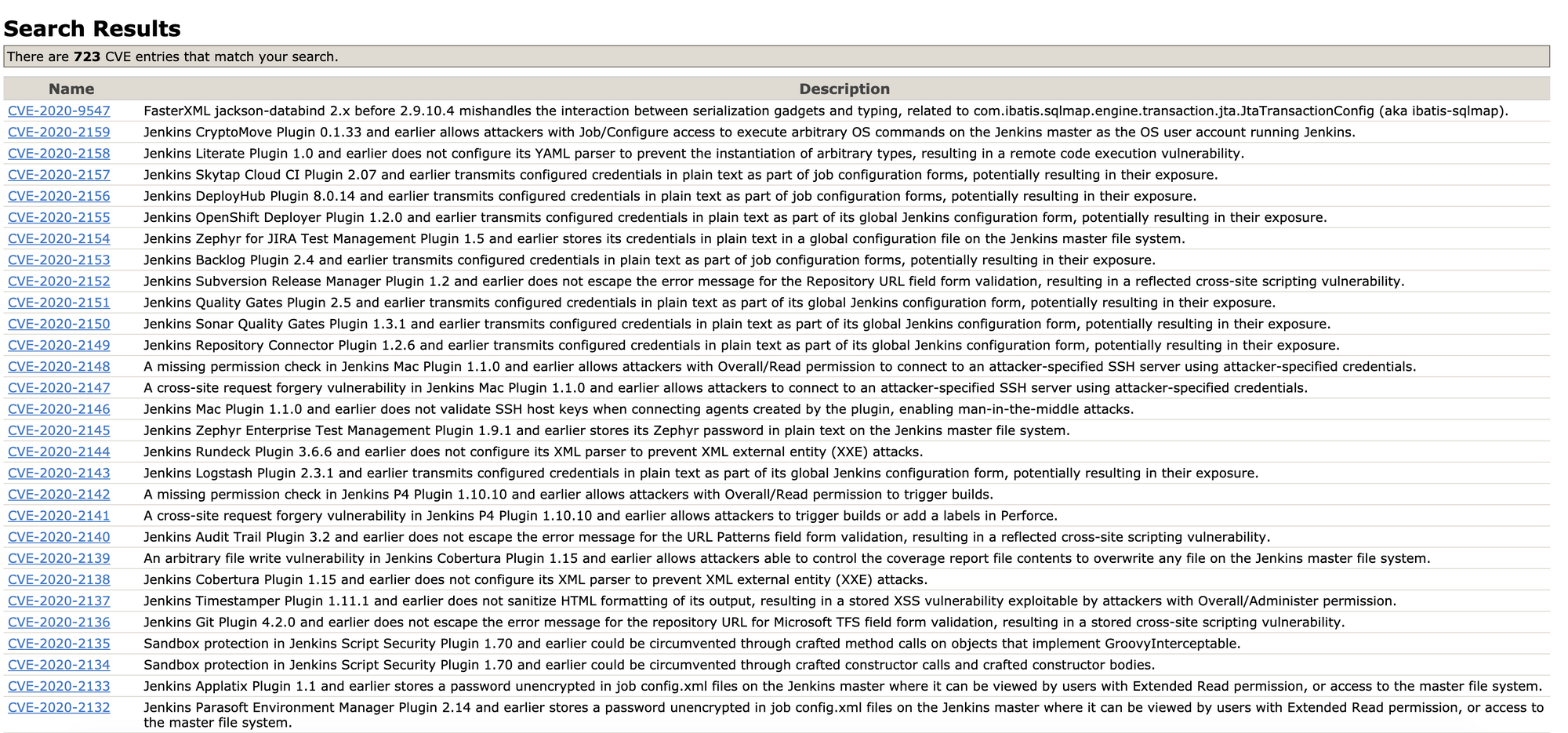
Persistent Infrastructure or "Centralized" CI Tools are often vulnerable to several security flaws.
These flaws are amplified by the fact that they are security flaws that cause Code Execution on a Code Execution Platform. Go figure 🤷🏻
In addition, its much harder to do:
- Granular Access Control => I cannot count the times that Jenkins Administrators have acted like allowing someone else to run a job on Jenkins would result in a contagion worse than the COVID19
- Secrets Management => Running Ephemeral infrastructure, either on-prem, or even better on cloud, is much better from a secrets management perspective. A single CI service that controls everything, getting popped is not good for secrets. For example, all my event-driven DevSecOps jobs are backed by Amazon's Secrets Manager, which can be locked down quite comprehensively with IAM privileges. For on-prem/Kubernetes stuff, I love working with Hashicorp Vault, which gives you the benefit of similar capabilities and several more, depending on how you'd use it
Finally, Feedback-driven systems are more flexible to needs of different teams. We, at we45, work with product companies for DevSecOps implementations, where each engineering team has a completely autonomous way of working and releasing code. They work with:
- different deployment environments
- different stacks
- different platforms
- different databases
- different team dynamics among other things
Yet, strangely enough, are expected to use a homogenous CI/CD setup for their DevOps activities. This vexes me. Always. And it quite frankly vexes them. They, unfortunately, struggle, fret and fume till they run "Shadow DevOps" and take matters into their own hands.
In Conclusion
Think of DevOps (and consequently) DevSecOps as an empowering tool for your engineering team. And I think that comes down to Feedback.
- Feedback is better when its decentralized.
- Feedback is asynchronous (event-driven)
- Feedback is flexible and replaceable (with another type/form of feedback)
To learn hands-on techniques and work with intensive labs. Consider enrolling in our training this year at BlackHat USA 2020 at Las Vegas. Early bird prices are in effect right now. Register here!